
尚书七号是一款专门为识别图片中的文字而研发的软件,该软件采用OCR技术,为满足书籍、报刊杂志、报盘票据、公文档案等录入需求,实现系统管理方式而设计的软件系统,尚书七号ocr免费版适用于个人、小型图书馆、小型档案馆、小型企业进行大规模文档输入、图书翻印、大量资料电子化的软件系统。
识别字符 简体字符集:国标GB2312-80的全部一、二级汉字6800多个。纯英文字符集。 简繁字集:除了简体汉字外,还可以混识台湾繁体字5400多个以及香港繁体字和GBK汉字。
识别字体种类 能识别宋体、仿宋、楷、黑、魏碑、隶书、圆体、行楷等一百多种字体,并支持多种字体混排。
识别字号 初号 小六号字体。
表格识别 可以自动判断、拆分、识别和还原各种通用型印刷体表格。
尚书七号ocr可支持繁体WINDOWS系统
小角度开启装订成册的扫描对象,对扫描对象没有损坏。全幅无盲区、无变形、无黑边,获得完整的图像结果。适合于不拆装批量连续扫描,得到的图像不会歪斜。
扫描速度
在200dpi的常用分辨率下,XT3588 只需要不到1.4秒的时间,就可以完成一张A4影像的彩色扫描。
自动文稿侦测,即放即扫
自动感应探测器的设计,不定时侦测扫描区域,即放即扫。用户还可根据个人操作习惯,设置感应灵敏度,以调整扫描间隔时间。对于日扫描量比较大的用户,如图书馆或数据加工,此功能很实用,成倍节省工作时间,提高工作效率。
快捷操作
XT3588 提供三个功能按键,用户可以根据使用习惯的不同,自行设定每个按键的功能。无需繁琐的操作,只要轻触按键,即可完成扫描、复制或OCR识别等操作。这种设计不仅能大幅提高工作效率,更能降低使用门槛,即使对初学者也可以轻松操作。
MICROTEK ScanWizard DI(MICROTEK 自动图文扫描工具处理软件)是一款有效便捷、功能强大的扫描软件,集扫描驱动与常用影像处理工具于一体,专门针对文档类应用而开发,是中晶科技二十年影像处理技术的结晶。随着客户应用不断拓展,ScanWizard DI功能将持续有效的更新,以提高客户工作效率为最终目标,日益深化。
支持双层PDF格式
扫描影像经过去污、纠偏、OCR识别,直接生成可检索的PDF文件。此PDF文件分两双层,上层是原始图像,下层是识别结果,用户可选择、复制、检索等,便于建立索引数据库,进行科学管理。
文件底色淡化功能
淡化红、绿、蓝、黄等文件底色,使文字更清晰,便于阅读及识别。
多数据流输出功能
只需一次扫描,就能同时得到彩色+黑白+灰阶三种影像。彩色图像清晰用于辨识、查看等,黑白图像文件较小利于存档,灰阶图像文件有亮度层次同样也利于存档。此功能也支援多种自定义组合影像选择,同时输出不同格式影像。
选择安装的地址(一定不要放在系统盘里哦),然后点击下一步
请耐心等待^o^
完成后请按自己喜欢选择即可使用Y(^_^)Y
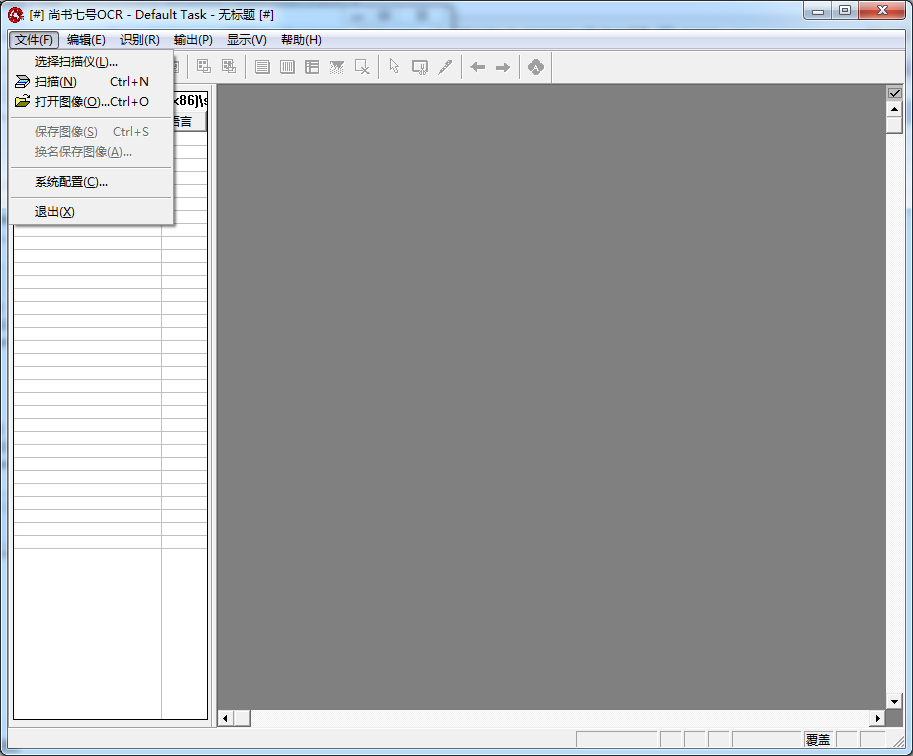
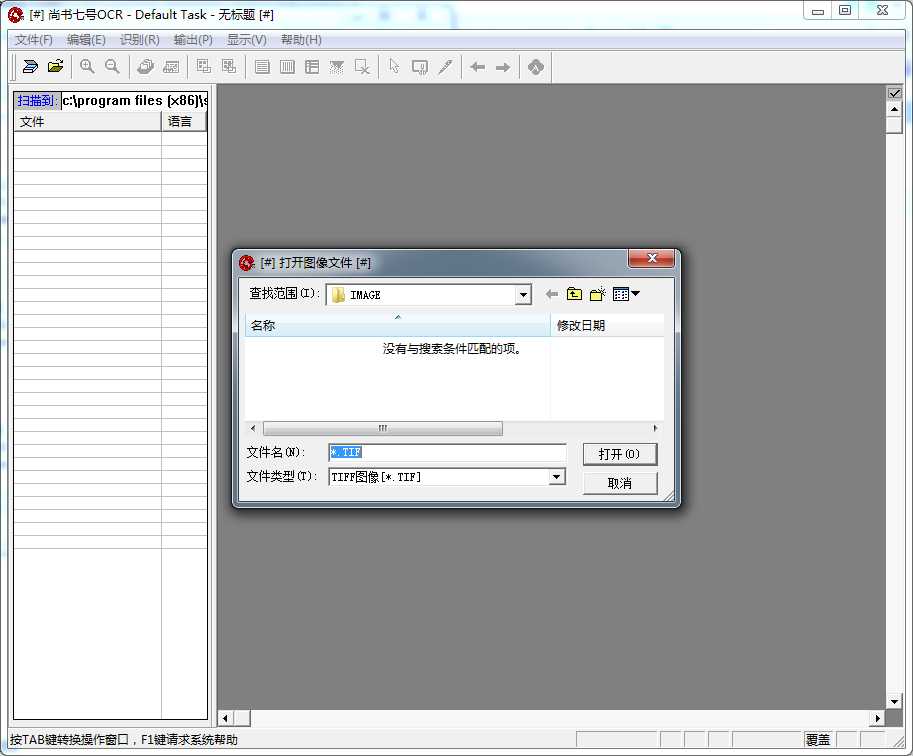
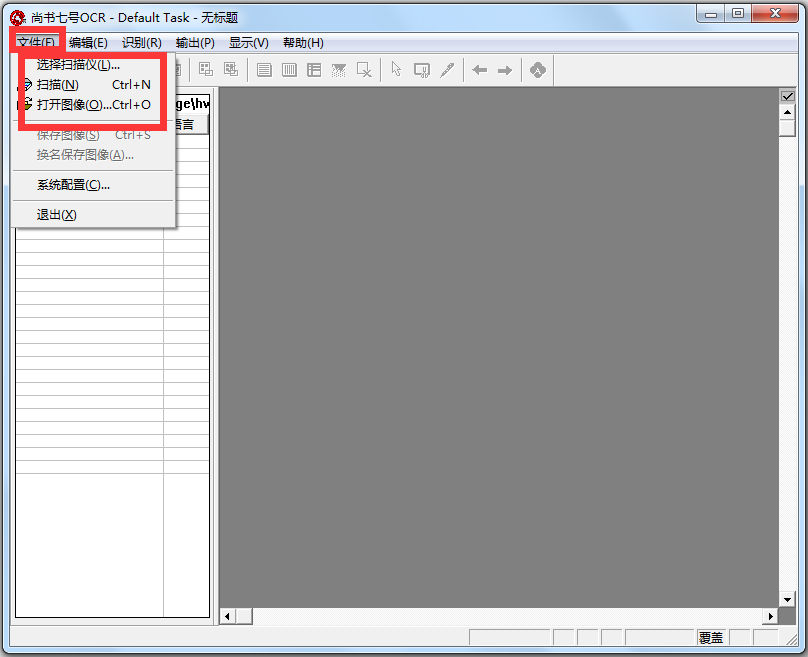
步骤1:获取文字图像文件
选择“文件”菜单下的“扫描”或“打开图像”(将已经扫描好的图像文件打开)命令,打开图像文件。如果连接了多台扫描仪,可以选择“文件”菜单下的“选择扫描仪”命令,调用扫描仪。
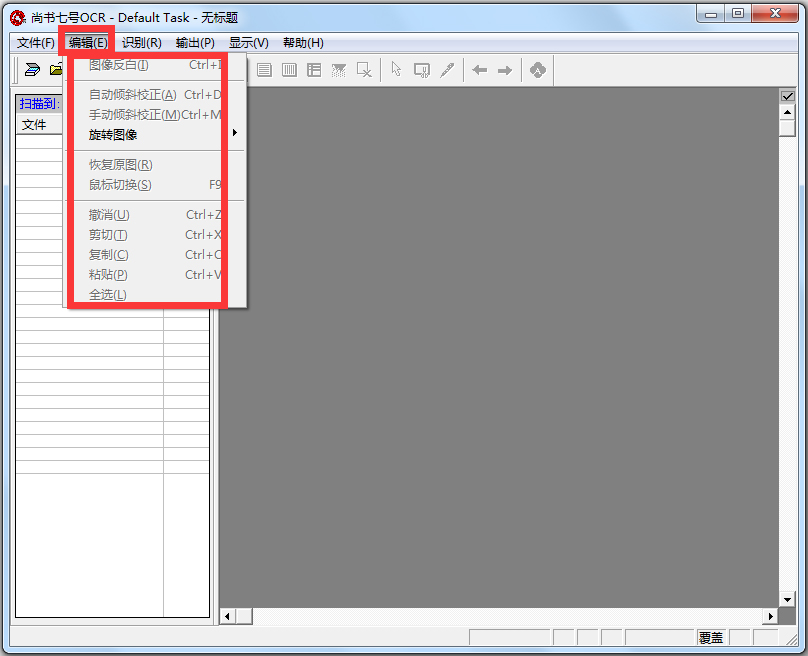
步骤2:对扫描的图像页进行调整
选择“编辑”菜单下“图像页面的处理”子菜单下的“图像页的倾斜校正”(提供自动和手动实现方法)及“旋转”等命令,将扫描的图像页进行调整。
步骤3:版面分析与文字识别转化
版面分析,选择识别范围,在进行文字识别前要选择识别范围,识别过程的核心是“版面分析”。
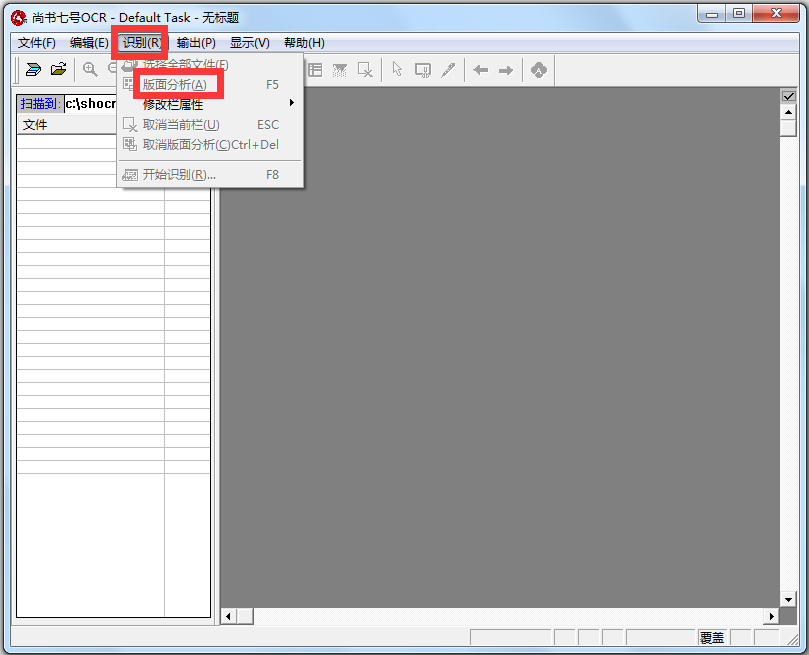
尚书七号的自动版面分析功能很强,对报纸杂志等复杂的版面,也能保持很高的分析正确率。
设置好后,直接点击“开始识别”的按钮就可以进行文字识别了。
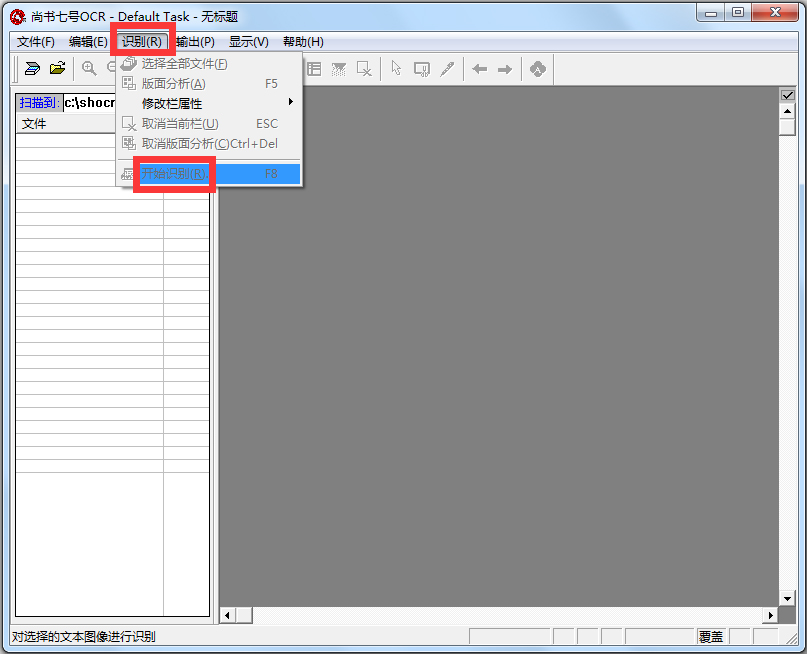
步骤4:校对修改
自动识别完毕,识别结果的“文本窗口”会弹出,这个窗口能够提供识别结果的校对,为了校对方便,尚书七号增加了光标跟随显示原图像行的校对方法(如图3出现的黄色提示行的出现)。
提供的校对方法,一眼就能够看到图像原文和识别出文本的差别,如果发现识别有误,可以进行修改。
步骤5:输出
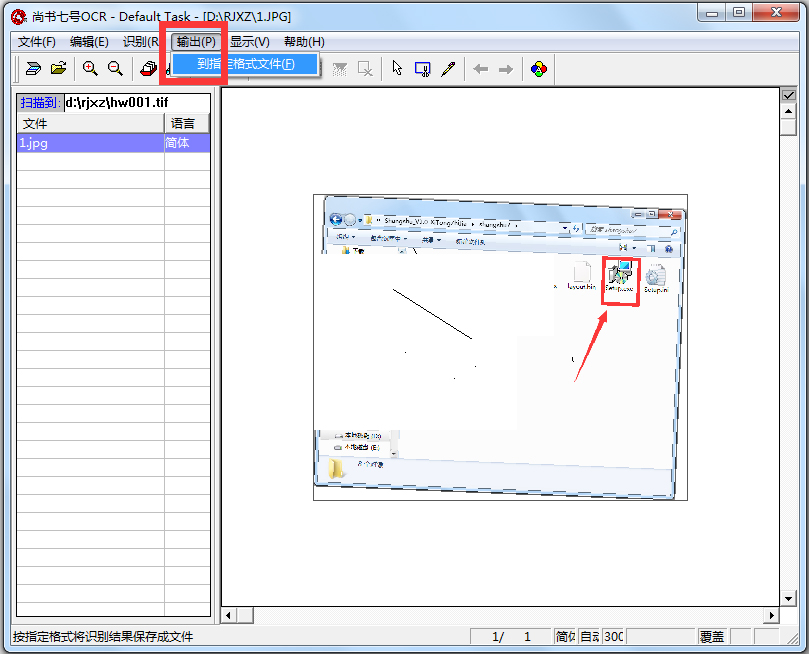
如果检查修改后确认无误,选择识别结果的“输出”菜单,输出的文件格式有:RTF、HTML、XLS、22238,可以根据自己的需要选择对应的格式。如果用户想得到类似原文的识别结果,请选择RTF格式。把RTF格式输出的文件用WORD打开后,会发现几乎保留了原文的所有痕迹,包括原来页面中的彩色图像,都已经保留在WORD中了。
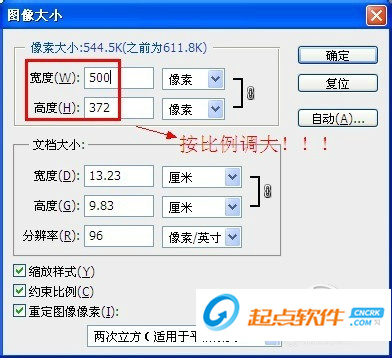
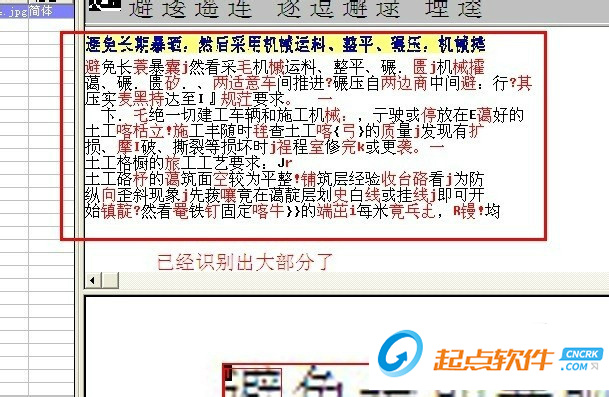
1、识别图片时如果全部显示乱码,说明图片的分辨率较低,无法识别。
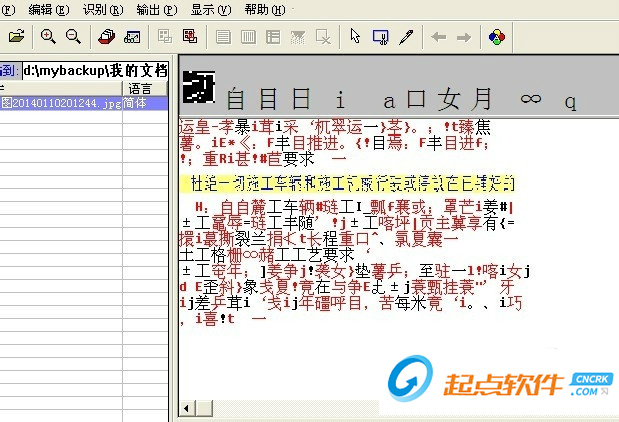
2、可以用photoshop把图片分辨率调大,这样分辨率高了,就算看起来不清晰,也可以使用
二、识别之后是斜的,怎么校正?
1、点击软件左上角的文件
2、选择里面的系统配置
3、点击“识别”
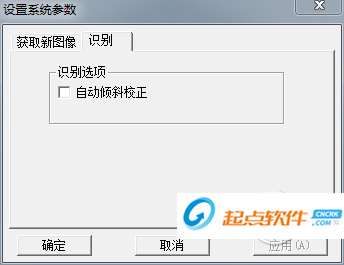
4、勾选自动倾斜校正
5、之后的文件就可以自动校正啦
【软件特色】
尚书七号下载系统正是适用于个人、小型图书馆、小型档案馆、小型企业进行大规模文档输入、图书翻印、大量资料电子化的软件系统。识别字符 简体字符集:国标GB2312-80的全部一、二级汉字6800多个。纯英文字符集。 简繁字集:除了简体汉字外,还可以混识台湾繁体字5400多个以及香港繁体字和GBK汉字。
识别字体种类 能识别宋体、仿宋、楷、黑、魏碑、隶书、圆体、行楷等一百多种字体,并支持多种字体混排。
识别字号 初号 小六号字体。
表格识别 可以自动判断、拆分、识别和还原各种通用型印刷体表格。
尚书七号ocr可支持繁体WINDOWS系统
【软件功能】
短边际设计小角度开启装订成册的扫描对象,对扫描对象没有损坏。全幅无盲区、无变形、无黑边,获得完整的图像结果。适合于不拆装批量连续扫描,得到的图像不会歪斜。
扫描速度
在200dpi的常用分辨率下,XT3588 只需要不到1.4秒的时间,就可以完成一张A4影像的彩色扫描。
自动文稿侦测,即放即扫
自动感应探测器的设计,不定时侦测扫描区域,即放即扫。用户还可根据个人操作习惯,设置感应灵敏度,以调整扫描间隔时间。对于日扫描量比较大的用户,如图书馆或数据加工,此功能很实用,成倍节省工作时间,提高工作效率。
快捷操作
XT3588 提供三个功能按键,用户可以根据使用习惯的不同,自行设定每个按键的功能。无需繁琐的操作,只要轻触按键,即可完成扫描、复制或OCR识别等操作。这种设计不仅能大幅提高工作效率,更能降低使用门槛,即使对初学者也可以轻松操作。
MICROTEK ScanWizard DI(MICROTEK 自动图文扫描工具处理软件)是一款有效便捷、功能强大的扫描软件,集扫描驱动与常用影像处理工具于一体,专门针对文档类应用而开发,是中晶科技二十年影像处理技术的结晶。随着客户应用不断拓展,ScanWizard DI功能将持续有效的更新,以提高客户工作效率为最终目标,日益深化。
支持双层PDF格式
扫描影像经过去污、纠偏、OCR识别,直接生成可检索的PDF文件。此PDF文件分两双层,上层是原始图像,下层是识别结果,用户可选择、复制、检索等,便于建立索引数据库,进行科学管理。
文件底色淡化功能
淡化红、绿、蓝、黄等文件底色,使文字更清晰,便于阅读及识别。
多数据流输出功能
只需一次扫描,就能同时得到彩色+黑白+灰阶三种影像。彩色图像清晰用于辨识、查看等,黑白图像文件较小利于存档,灰阶图像文件有亮度层次同样也利于存档。此功能也支援多种自定义组合影像选择,同时输出不同格式影像。
【安装步骤】
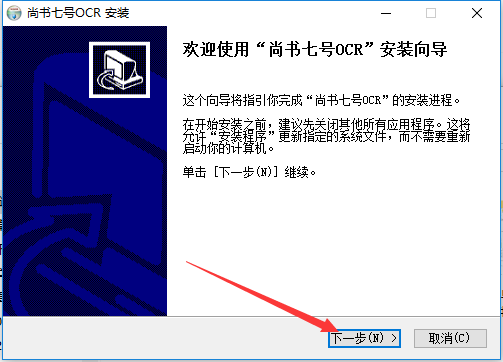
打开软件程序选择安装的地址(一定不要放在系统盘里哦),然后点击下一步
请耐心等待^o^
完成后请按自己喜欢选择即可使用Y(^_^)Y
【使用方法】
用扫描仪扫描的文字图像,不能对个别文字进行编辑修改,在教学中,需要利用文字识别软件,将文字图像进行识别,将图像格式转化成文本格式,常见的文字识别软件有很多,主要功能基本相同,尚书七号就是其中很优秀的一款。用尚书七号对文字图像识别转化的过程,利用其主菜单:“文件”、“编辑”、“识别”、“输出”可以很方便地完成。具体步骤为:步骤1:获取文字图像文件
选择“文件”菜单下的“扫描”或“打开图像”(将已经扫描好的图像文件打开)命令,打开图像文件。如果连接了多台扫描仪,可以选择“文件”菜单下的“选择扫描仪”命令,调用扫描仪。
步骤2:对扫描的图像页进行调整
选择“编辑”菜单下“图像页面的处理”子菜单下的“图像页的倾斜校正”(提供自动和手动实现方法)及“旋转”等命令,将扫描的图像页进行调整。
步骤3:版面分析与文字识别转化
版面分析,选择识别范围,在进行文字识别前要选择识别范围,识别过程的核心是“版面分析”。
尚书七号的自动版面分析功能很强,对报纸杂志等复杂的版面,也能保持很高的分析正确率。
设置好后,直接点击“开始识别”的按钮就可以进行文字识别了。
步骤4:校对修改
自动识别完毕,识别结果的“文本窗口”会弹出,这个窗口能够提供识别结果的校对,为了校对方便,尚书七号增加了光标跟随显示原图像行的校对方法(如图3出现的黄色提示行的出现)。
提供的校对方法,一眼就能够看到图像原文和识别出文本的差别,如果发现识别有误,可以进行修改。
步骤5:输出
如果检查修改后确认无误,选择识别结果的“输出”菜单,输出的文件格式有:RTF、HTML、XLS、22238,可以根据自己的需要选择对应的格式。如果用户想得到类似原文的识别结果,请选择RTF格式。把RTF格式输出的文件用WORD打开后,会发现几乎保留了原文的所有痕迹,包括原来页面中的彩色图像,都已经保留在WORD中了。
【常见问题】
一、识别的图片显示乱码1、识别图片时如果全部显示乱码,说明图片的分辨率较低,无法识别。
2、可以用photoshop把图片分辨率调大,这样分辨率高了,就算看起来不清晰,也可以使用
二、识别之后是斜的,怎么校正?
1、点击软件左上角的文件
2、选择里面的系统配置
3、点击“识别”
4、勾选自动倾斜校正
5、之后的文件就可以自动校正啦



































