
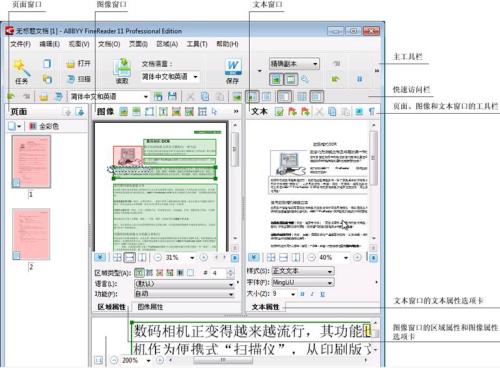
abbyy finereader 11是一款非常实用的文档识别类软件,用户可以在线修改相关电子数据,给您的文件打印带来更多的便利。并且软件轻便上手,给更多的用户节约办公上的时间。
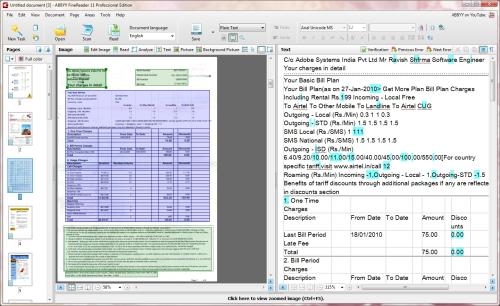
finereader11中文版不仅支持多国文字,还支持彩色文件识别,让用户能够获得原汁原味的内容,而且还能够保留原稿件插图和排版格式等等,使用者再也不需要使用扫描软件、扫描仪、OCR、Word等等软件转换来转还去了。finereader11中文版处理过后的文件再启动和加载方面也非常的快速便捷,我们的用户能够节省许多时间在打开文件上。
如果你是一位办公人员或者文员之类的需要天天跟各种格式的文档打交道,那么这款软件将是非常不错的选择。
ABBYY FineReader 8.0 提供出色的识别率和版面还原,即使面对读取困难的或低品质的文档也如此。 FineReader 完美的获取并且重建所有的格式化要素(包括分栏、表格、列表和图象) –你无需重新打字或重新排版。
OCR
可以将数码相机列入到移动文档捕获设备里。您可以使用数码相机获取文件并将其转换为可重用信息。
ABBYY FineReader 可以智能识别被拍摄的文档并且应用 ABBYY 的新的识别技术以保证数码相机图象能得到最佳的OCR[1] 结果。 因为有数码相机OCR, FineReader 提供了广泛的可能性来迅速获取文档并将其转换成可编辑和可搜索的电子文件,即使在您忙个不停的时候。使用数码相机来 OCR,您能不受传统扫描设备的限制。您能从大海报或从厚重、精装的文档,如书中获取文本,而这类文档是很难扫描的。另外,使用数码相机获取文档是非常高效的,比扫描快几倍。
PDF 转换
ABBYY FineReader 8.0 是一个理想的 PDF 转换工具。它在一个应用程序中提供三个不同的PDF转换功能:
1)PDF编辑
打开 PDF 文件并且转换它成可编辑的格式(例如 Microsoft Word 或 Excel),执行少量正文编辑,然后保存回 PDF。
2)纸上文档创建可搜索的 PDF 文件。
3)加密 PDF
ABBYY FineReader 遵照了最新的加密标准。用 FineReader,您能创建加密的 PDF 文件,带有用先进加密标准(AES)创建的最高 128 位加密。FineReader 也遵从访问权限保护: 当打开一个 PDF 文件要转换时,FineReader 会提示用户在执行之前输入密码。
一键 OCR
用新增的自动操作管理器,您可用鼠标的唯一单击执行完全的转换任务。ABBYY FineReader 内置了针对最普通的文档处理流程的计划任务,包括扫描(及 OCR)到 Word,扫描到 PDF,及 PDF 到 Word。
您也可以使用自动化向导来创建您自己的自定义任务。向导会引导您通过创建新任务的步骤。任务可以在ABBYY FineReader 8.0 中使用命令和选项进行自定义和微调,因此您能迅速和容易地自动化甚至于最特别的任务。例如,您可以指定一个任务来扫描文档,载入模板,进行OCR,然后保存结果到 Word 和 PDF,并像原始图象一样,保存在不同的文件夹中。
自动任务可以容易地被导入和导出。一旦您创建了一些有用的自动任务,您可以将其导出为文件并与您的同事和朋友分享。
多语言识别
ABBYY FineReader 支持 179 种语言,包括英语、德语、法语、希腊语、西班牙语、意大利语、葡萄牙语、荷兰语,瑞典语,芬兰语,俄语,乌克兰语,保加利亚语,捷克语,匈牙利语,波兰语、斯洛伐克语、马来语,印度尼西亚语和其他。内置拼写检查可以支持其中36种语言。这为与各种各样不同的国家(地区)和文化打交道的人简化了文档转换过程。
注意:已推出简体中文专业版和企业版,完美支持中文。
多保存格式
当您转换文档来编辑时,ABBYY FineReader 8.0 可以直接地向您喜爱的应用导出结果,包括 Microsoft Word、Microsoft Excel、Microsoft PowerPoint、Lotus Word Pro、Corel WordPerfect、Sun StarWriter 和 Adobe Acrobat/Reader。另外,识别的的文本可以被保存为各种各样的文件格式,包括 PDF, HTML, Microsoft Word XML、DOC、RTF、XLS、PPT、DBF、CSV、TXT 和 LIT。
附加程序
为即时 OCR 附加的 ABBYY Screenshot Reader 实用程序
ABBYY Screenshot Reader 是一个易用的工具,可以让您迅速获取屏幕图像并且允许您从屏幕进行“即时” OCR。它对摘取文本、表格或者浏览器页面图像、flash 介绍, Windows Explorer “文件”菜单或者错误消息来说是很理想的。当您想要从 PDF 或图像文件摘取小的节录或文本中的几个句子时, Screenshot Reader 也是一个理想的“快速 OCR”工具。作为对注册用户的奖励,ABBYY Screenshot Reader 与 ABBYY FineReader 8.0 专业版同时发行。
与Word 协同
您可以从 Microsoft Word 内部启动 ABBYY FineReader,扫描纸质文档并将识别结果置入您正在操作的文档中而不用离开 Word。
当导出文件到 Microsoft Word 2003 时, FineReader 自动地打开原文件的一张嵌入视图,允许您同时编辑和查验您的文档,这就不需要在两种应用程序之间切换。
文本编辑
多分栏所见即所得文本编辑器允许您在编辑期间查看扫描文档的完整版式,因此您可以在导出它之前迅速检查文件。
全文搜索
在 ABBYY FineReader 中创建的任何批处理文件都可以作为一个带有全文搜索功能的小数据库使用。您可以用所有语法形式搜索单词。此功能支持有词典支持的36种语言。
条型码识别
ABBYY FineReader 也支持条型码识别,包括 PDF-417 2D 条码的识别。这对需要处理并索引很大数量的文档为存档的公司来说是很理想的功能。
图像分割工具
图像分割工具允许您分割图像为几个区域并保存各个区域为单独页面。此模式对识别书籍和 PowerPoint 稿件是非常方便的。
易用性
ABBYY FineReader 8.0 有一个新的直观的,友好的用户界面来指引您通过 OCR 过程。 无论您对 OCR 是陌生的还是一个高级用户,使用 FineReader 8.0 工作都是简单和容易的。
支持的部分语言列表:
带有词典支持的语言:
亚美尼亚语(东部,西部,Grabar) 保加利亚语 巴士克语 加泰罗尼亚语克罗地亚语捷克语
荷兰语 (荷兰和比利时) 英语 爱沙尼亚语 芬兰语 法语 希腊语
德语 (新拼法和古拼法) 丹麦语 匈牙利语 意大利语 拉脱维亚语立陶宛语
挪威语 (尼诺斯克语和博克马尔语) 波兰语 罗马尼亚语 俄语 斯洛伐克语 西班牙语
葡萄牙语 (葡萄牙和巴西) 斯洛文尼亚语 瑞典语鞑靼语土耳其语乌克兰语
人工语言:
世界语(Esperanto) 拉丁国际语(Interlingua) 伊多语(Ido) 西方语(Occidental)
格式化语言:
Basic
C/C++
COBOL
Fortran
JAVA
Pascal
简单化学公式(H2O, C2H5OH)
通过使用全新的黑白模式,当您不需要彩色时,FineReader 11 提供的处理速度提高 30%。此外,该程序有效利用了多核处理器的优势,使转换速度更快。
创建电子书灵活多变
扫描纸质书并将它们转换为 ePub 和 fb2 格式,以便在路途上用您的 iPad、平板电脑或最喜欢的便携设备进行阅读。或者,直接将它们发送至您的 Kindle 帐户。将纸质书或文章转换为相应的电子书格式,以便将它们添加到您的电子图书馆或档案中。
Office支持
FineReader 11 将文档和 PDF 文件的图像直接识别和转换为 OpenOffice Writer 格式
(ODT),准确保留它们的本机布局及格式。您只需点击几次鼠标就可以轻松地将文档添加到您
的 *.odt 档案。
增强用户界面
增强的样式编辑器允许您在一个界面友好的窗口中设置所有样式参数。所有的更改会立即应用于整个文档。
在 FineReader 文档中组织页面,从而获取更佳的布局保留。
当程序启动后,立即启动文档转换,就可以更容易访问所有基本或高级转换任务。
配备有强大的图像编辑工具扩充组的下一代相机 OCR
FineReader 11 提供了一套强大的的新图像编辑工具,包括亮度和对比度滑块以及水平工具,确保您能获得更准确的结果并提高图像参数。
OCR 准确度
由于可更好地检测文档样式、脚注、页眉、页脚和图片标题,最大程度地减少编辑已转换文档所需的时间。
优化PDF 输出
PDF 文件的三个预定义的图像设置根据您的需求提供了优化的结果 – 最好的质量、压缩大小或平衡模式。新识别语言阿拉伯语、越南语和土库曼语(拉丁字母 )。
支持名片输入
使用名片阅读器,快速将纸质名片转换为电子联系人(仅 Corporate Edition 提供此功能)
从本站下载解压Abbyy Finereader V11软件
这是我下载的,压缩包资源包括这两个文件
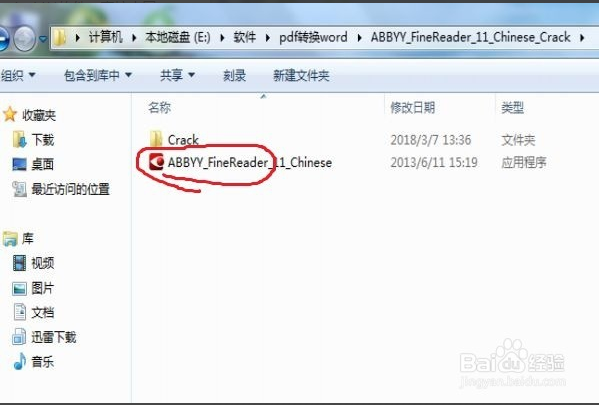
点击安装文件“ABBYY_FineReader_11_Chinese”,开始安装;弹出下图对话框,直接点击 "Install"即可。
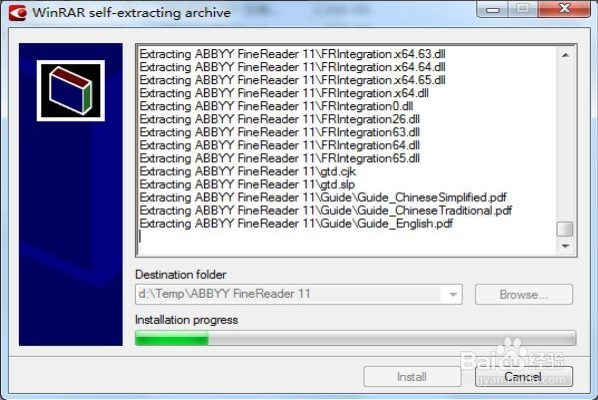
进入下图,直接按提示安装
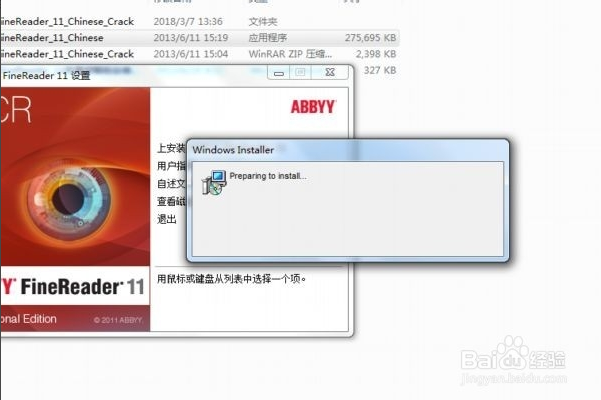
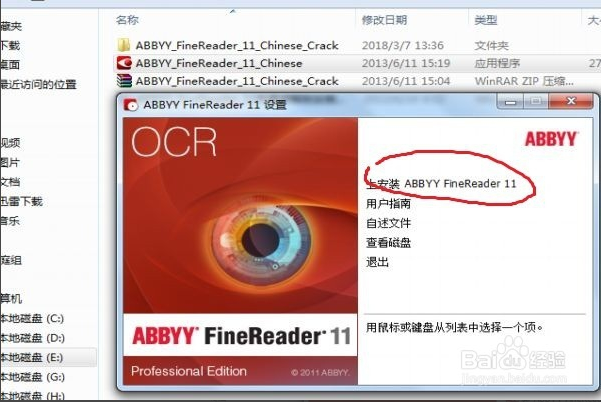
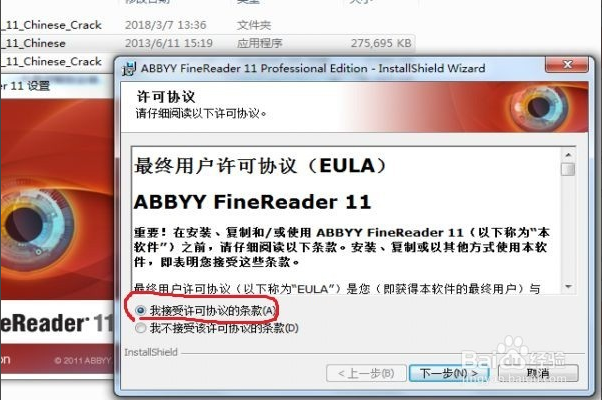
选“我接受”那项,进入界面“安装类型和位置”,选择“典型”安装
和自定义安装位置,一般不建议安装到系统盘
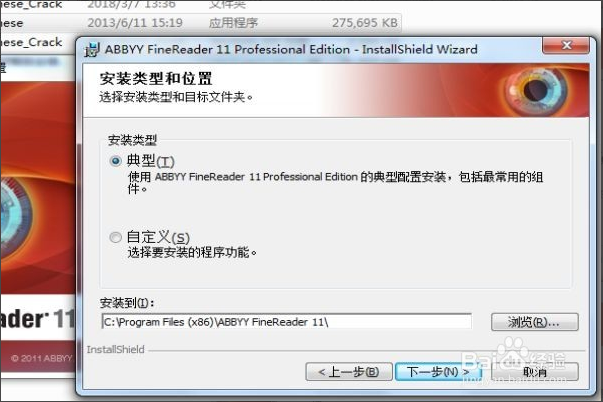
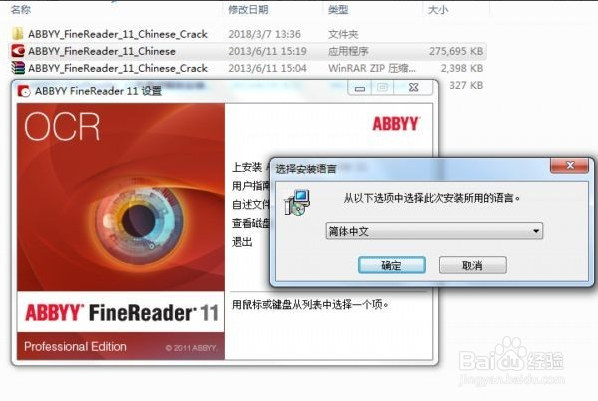
下图我用红圈圈的,根据自己需求选择,点击“安装”
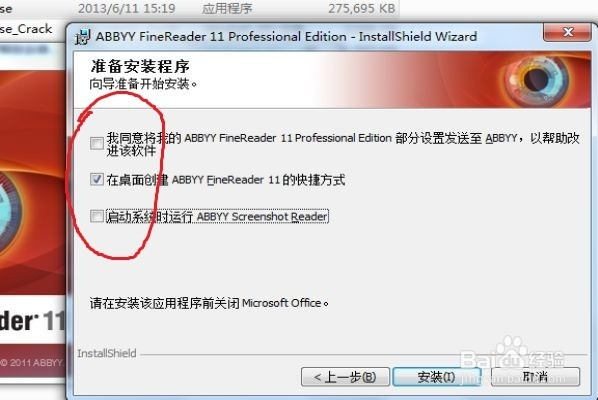
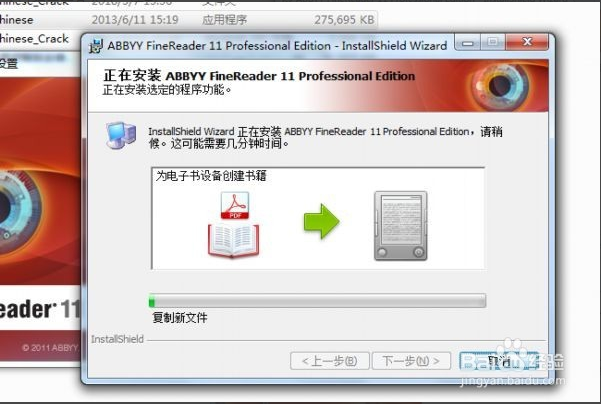
开始正式安装,这个过程需要几分钟,请耐心等待,直至安装完成。
制作PDF电子书文档
使用的是这个工具ABBYY FineReader 11
准备的图片格式的文档
准备的PDF格式的文档.
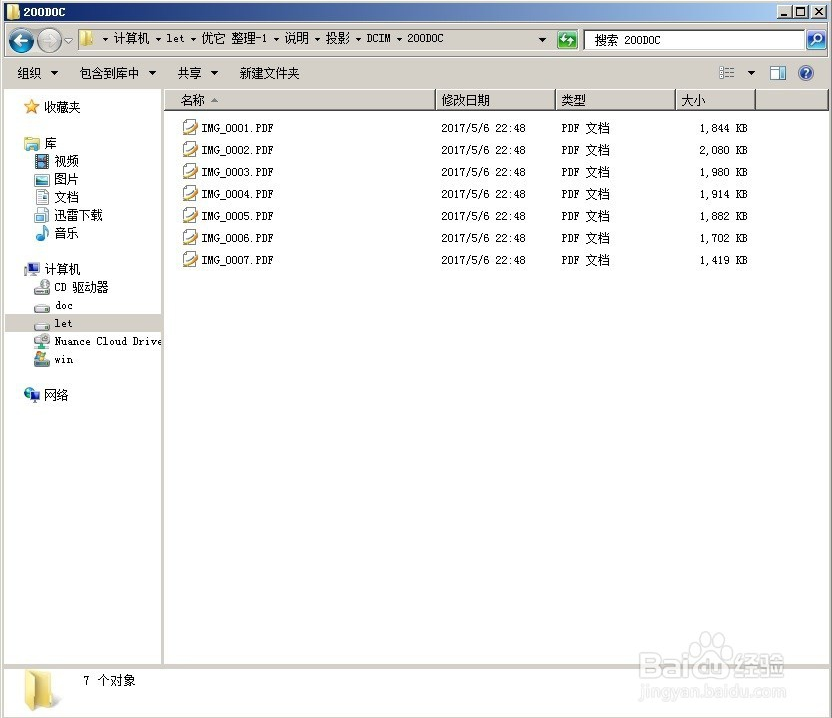
从图示可以看出PDF格式文档比JPG格式略大
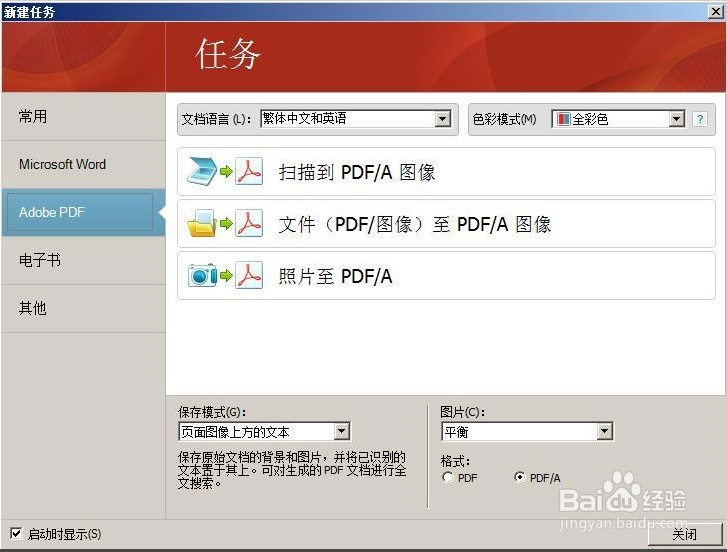
打开ABBYY FineReader 11软件,点击左上角文件菜单中“新建文档”选项,可调出“新建任务”面板,我们选择第二项“Adobe PDF”,其中有三个选项“扫描到PDF/A图像”、“文件(PDF/图像)至PDF/A图像”、“照片至PDF/A”,其中我们选择第二项”、“文件(PDF/图像)至PDF/A图像“,这一步骤的目的是把文件或图片转化为PDF电子书格式
选择文件打开后,出现“生成中”、“正在识别该文档”字样,等待进度条走完即可。
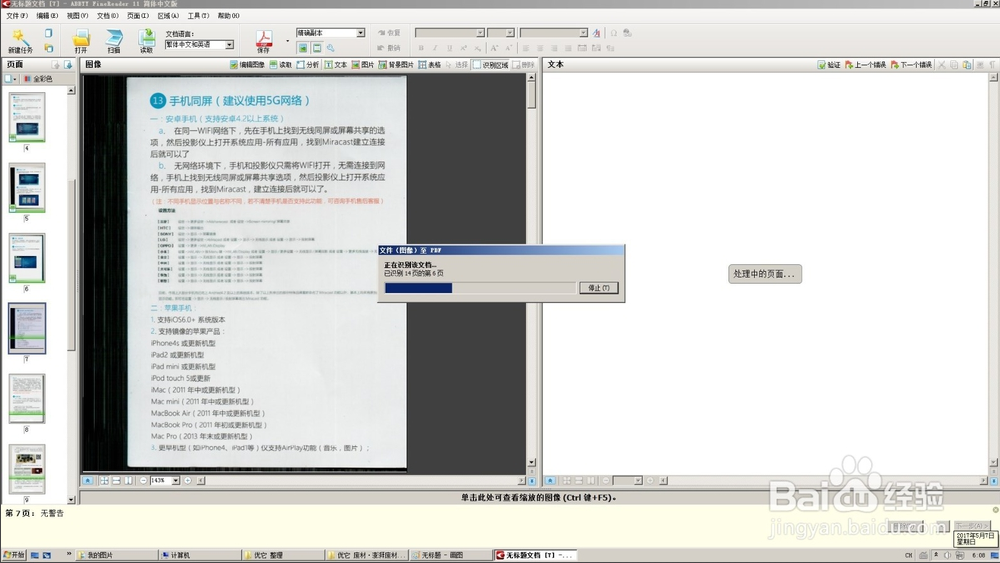
处理完成可能出现未识别字符字样,我也不知道怎么处理,好像也没啥影响。
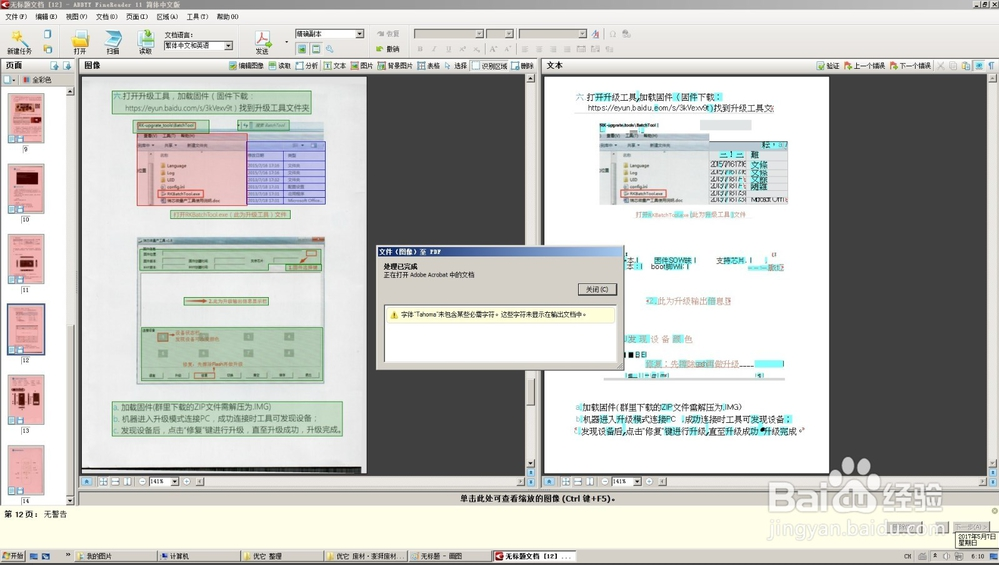
图片文档处理结束出现的是更正分辨率字样,这个我也不清楚是怎么回事儿,但文档确实是处理完也处理好了
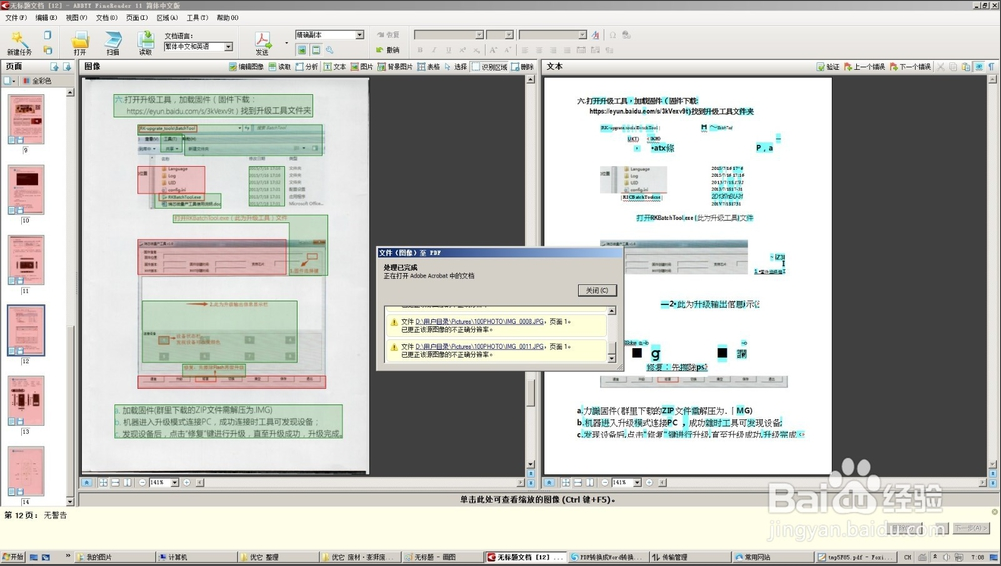
然后保存文档即可。我们这样保存:鼠标点击文件菜单下选择“将文档另存为”选项下“PDF/A文档”选项并确定,即可得到需要的PDF文件了。
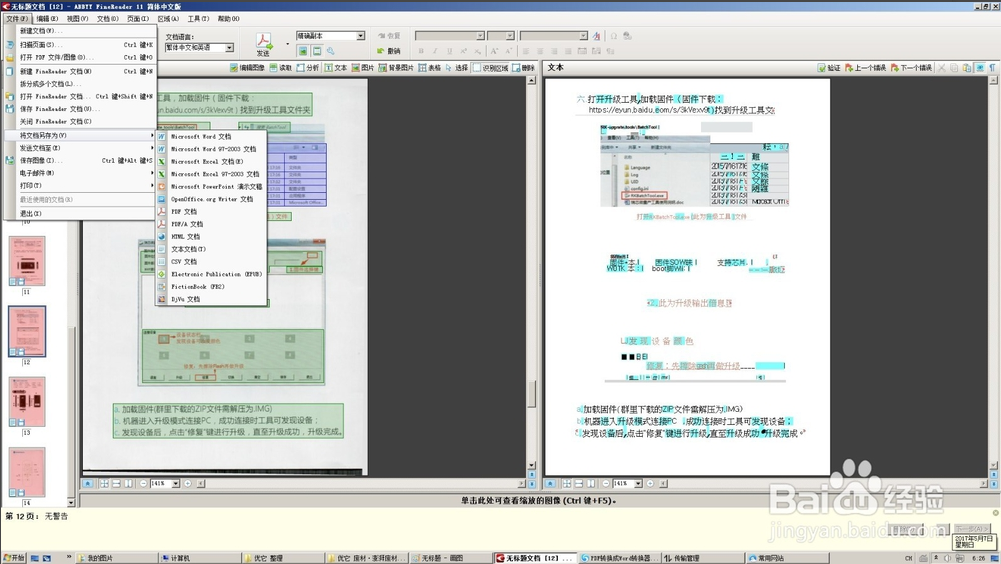
把PDF转成可编辑文件
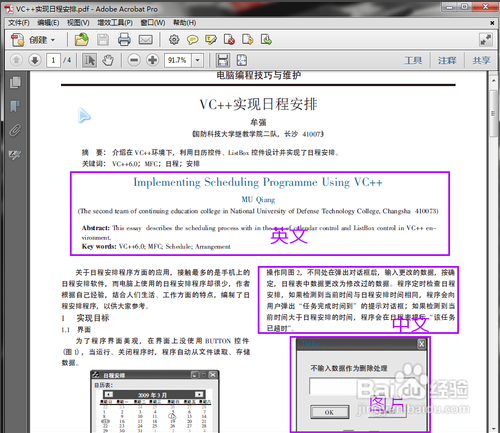
首先我们要做的就是打开一个需要转换的PDF文件,然后看一下这个文件里面有几种语言,是不是有表格、图片等
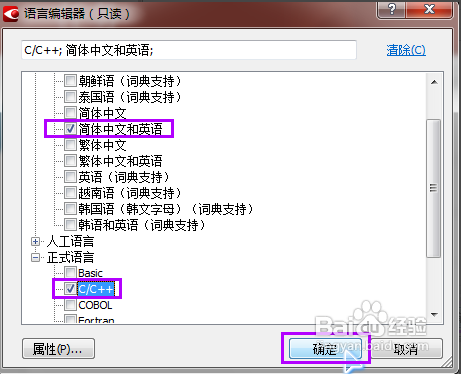
然后运行ABBYY finereader 11,点击欢迎界面“文档语言”下拉选择中的更多语言,弹出“语言编辑器”界面,我们设置好PDF文件中所包含的几种语言。
因为文件文件中有C++语言的内容,而ABBYY finereader 中正好也有C++的选择,那么我们就毫不犹豫的打上勾。设置完毕,点击右下角的“确定”按键。
回到任务界面,我们是想把PDF转成可编辑的word文件,所以我们点击中间的“文件(PDF/图片)到Microsoft Word”一项
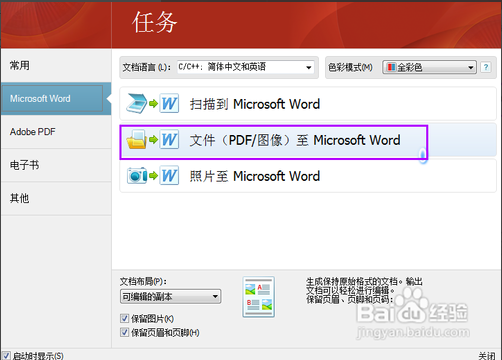
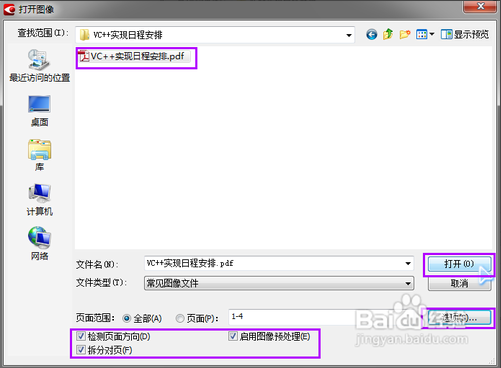
弹出文件选择窗口,选择需要转换的PDF文件,注意打开窗口的左下角那几个选项,默认都是打勾的,如果不需要的话可以去掉勾,然后点击“打开”按键。
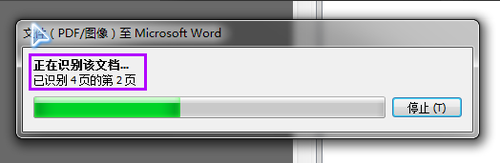
ABBYY finereader开始加载文件,并且自动OCR识别处理。如果页数比较多的话,可能需要花费一些时间,需要耐心等待一下。
由于自动识别会有一些错误,那么我就可以用手动工具进行修正。我们可以选择不同的工具来修正,比如表格被识别成了普通文字,中间没有线框了,那么我们选择“表格”工具,然后把文件中的表格的区域选出来,然后右键“读取区域”就能够手动识别成表格了。还有如果带有文字的图片被自动识别成了文字了,那么我们可以选择图片工具选出页面中的图片区域,然后在你识别本页面其他部分文字的时候,这个区域就会被识别成图片了。
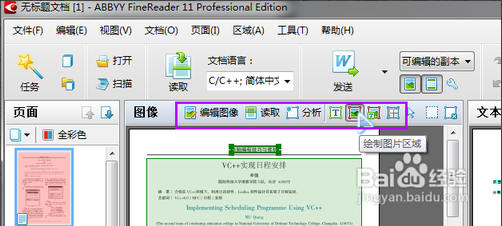
“编辑图像”按键是用来预处理扫描页图片的,因为扫描页有时候会有倾斜、对比度不好、变形等问题,那么先对图像修正一下可以大幅度提高识别的准确率,调整完以后点击右上角的“退出图像编辑器”按键就可以回到上一界面。
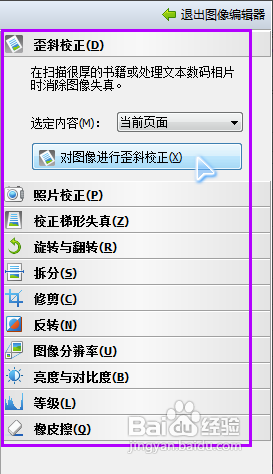
识别完毕以后,选择菜单来的“文件”---“将文档另存为”---“Microsoft Word文档”(如果你需要保存为其他格式你可以自己选择)。
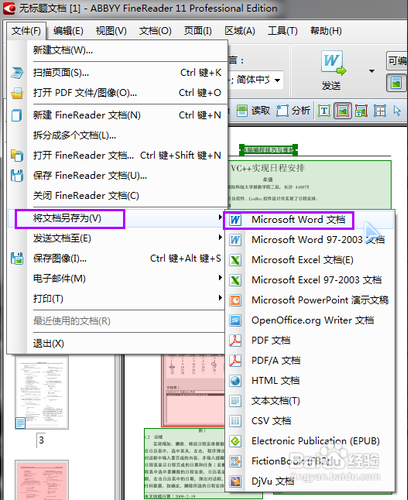
弹出保存对话框,选择保存路径,如果需要保存完就打开文件的话,记得勾选下面的“保存后打开文档”选项,如果电脑配置不高的话不建议勾选此项,因为ABBYY finereader本身比较耗内存,然后再打开word的话电脑可能会比较卡。保存完文件,转换过程就基本结束了。
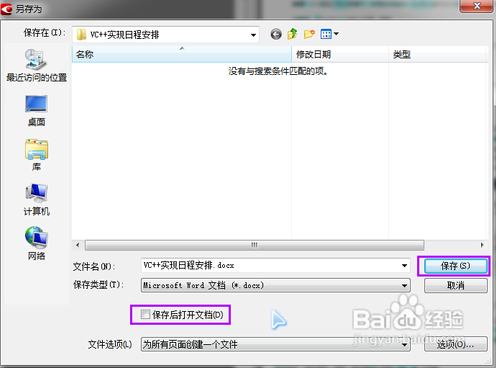
我们打开保存好的word文件,看看转换的效果怎么样。识别的区域基本上正常,中文英文、图像都可以识别出来,版面略微有些错位,不过还是含有部分错误,我们需要自己修改一下,但是这个已经可以大大降低我们的录入强度了。

假设你想要数字化一本杂志的文章或印刷合同。你可能需要花时间重新输入,然后纠正错字。或者,你可以使用扫描仪(或数码相机)和光学字符识别软件只需要花费几分钟转换成数字格式,的所有材料。
泰比(ABBYY) FineReader 11 简体中文版是泰比(ABBYY)专为中国市场设计的本地版本,拥有于全球最通用的泰比(ABBYY)FineReader 11 OCR文字识别软件等同的功能。
轻松一个点击即可生成电子化的文档!
泰比(ABBYY)FineReader提供直观的文件扫描和转换成可编辑、可搜索的电子格式工具。泰比(ABBYY)FineReader可以识别和转换几乎所有打印的文档类型,包括书籍、志上的文章与复杂的布局、表格和电子表格,甚至以准确的精度发传真。
使用ABBYY FineReader 11时我需要扫描仪吗?
不需要扫描仪。无需使用扫描仪来运行该程序,可以使用图像文件,如数码相机拍摄的照片,没有文本层的PDF文件。
什么样的扫描仪与FineReader 11兼容?
ABBYY FineReader 11支持所有TWAIN-和WIA-兼容的扫描仪,多功能周边设备(MFPs)和一体化设备,可以在Avision、Brother(兄弟)、Canon(佳能)、Epson(爱普生)、Fujitsu(富士通)、HP(惠普)、Kodak(柯达)、Lexmark、 Microtek、Mustek、Oki、Panasonic、Plustek、Ricoh、Visioneer、VuPoint、Xerox和其他很多品牌提供的型号中找到这样的扫描仪。
哪种设置是识别目的的最佳扫描设置?
标准文本(字体大小10及更大)300dpi分辨率,小号字体(9号及更小)文本400-600dpi分辨率,灰阶颜色模式。
ABBYY FineReader 11可以捕获手写文本吗?
ABBYY FineReader 11只能捕获打印文本。
软件重新安装之后激活码会发生改变吗?我需要重新购买吗?
软件重新安装之后激活码不变,除非电脑硬件配置发生大的变化—比如,如果电脑硬盘重新格式化了,或者操作系统重新安装或改变,在这种情况下需要再次激活程序,获取新的激活码。
“词典支持”是什么意思?
词典支持允许在单词层面二次分析文本元素,有了词典支持,程序可以确保更加精确的分析和文档识别,简化识别结果的进一步验证,ABBYY FineReader 12提供48种语言的词典支持。
【软件介绍】
finereader11中文版是一款俄罗斯开发的文档识别软件,而这家名为ABBYY的公司在文档识别、数据捕获和语言技术开发在世界上出于领先地位,可以说这款软件在OCR领域也是举足轻重的,有了这款软件用户可以轻而易举的完成静态纸张文件和pdf文档转换成可以进行编辑修改的电子数据,大大节省了用户的时间和精力,要不然用户可能就需要手动将里面的内容打出来了。finereader11中文版不仅支持多国文字,还支持彩色文件识别,让用户能够获得原汁原味的内容,而且还能够保留原稿件插图和排版格式等等,使用者再也不需要使用扫描软件、扫描仪、OCR、Word等等软件转换来转还去了。finereader11中文版处理过后的文件再启动和加载方面也非常的快速便捷,我们的用户能够节省许多时间在打开文件上。
如果你是一位办公人员或者文员之类的需要天天跟各种格式的文档打交道,那么这款软件将是非常不错的选择。
【软件功能】
识别率和版面ABBYY FineReader 8.0 提供出色的识别率和版面还原,即使面对读取困难的或低品质的文档也如此。 FineReader 完美的获取并且重建所有的格式化要素(包括分栏、表格、列表和图象) –你无需重新打字或重新排版。
OCR
可以将数码相机列入到移动文档捕获设备里。您可以使用数码相机获取文件并将其转换为可重用信息。
ABBYY FineReader 可以智能识别被拍摄的文档并且应用 ABBYY 的新的识别技术以保证数码相机图象能得到最佳的OCR[1] 结果。 因为有数码相机OCR, FineReader 提供了广泛的可能性来迅速获取文档并将其转换成可编辑和可搜索的电子文件,即使在您忙个不停的时候。使用数码相机来 OCR,您能不受传统扫描设备的限制。您能从大海报或从厚重、精装的文档,如书中获取文本,而这类文档是很难扫描的。另外,使用数码相机获取文档是非常高效的,比扫描快几倍。
PDF 转换
ABBYY FineReader 8.0 是一个理想的 PDF 转换工具。它在一个应用程序中提供三个不同的PDF转换功能:
1)PDF编辑
打开 PDF 文件并且转换它成可编辑的格式(例如 Microsoft Word 或 Excel),执行少量正文编辑,然后保存回 PDF。
2)纸上文档创建可搜索的 PDF 文件。
3)加密 PDF
ABBYY FineReader 遵照了最新的加密标准。用 FineReader,您能创建加密的 PDF 文件,带有用先进加密标准(AES)创建的最高 128 位加密。FineReader 也遵从访问权限保护: 当打开一个 PDF 文件要转换时,FineReader 会提示用户在执行之前输入密码。
一键 OCR
用新增的自动操作管理器,您可用鼠标的唯一单击执行完全的转换任务。ABBYY FineReader 内置了针对最普通的文档处理流程的计划任务,包括扫描(及 OCR)到 Word,扫描到 PDF,及 PDF 到 Word。
您也可以使用自动化向导来创建您自己的自定义任务。向导会引导您通过创建新任务的步骤。任务可以在ABBYY FineReader 8.0 中使用命令和选项进行自定义和微调,因此您能迅速和容易地自动化甚至于最特别的任务。例如,您可以指定一个任务来扫描文档,载入模板,进行OCR,然后保存结果到 Word 和 PDF,并像原始图象一样,保存在不同的文件夹中。
自动任务可以容易地被导入和导出。一旦您创建了一些有用的自动任务,您可以将其导出为文件并与您的同事和朋友分享。
多语言识别
ABBYY FineReader 支持 179 种语言,包括英语、德语、法语、希腊语、西班牙语、意大利语、葡萄牙语、荷兰语,瑞典语,芬兰语,俄语,乌克兰语,保加利亚语,捷克语,匈牙利语,波兰语、斯洛伐克语、马来语,印度尼西亚语和其他。内置拼写检查可以支持其中36种语言。这为与各种各样不同的国家(地区)和文化打交道的人简化了文档转换过程。
注意:已推出简体中文专业版和企业版,完美支持中文。
多保存格式
当您转换文档来编辑时,ABBYY FineReader 8.0 可以直接地向您喜爱的应用导出结果,包括 Microsoft Word、Microsoft Excel、Microsoft PowerPoint、Lotus Word Pro、Corel WordPerfect、Sun StarWriter 和 Adobe Acrobat/Reader。另外,识别的的文本可以被保存为各种各样的文件格式,包括 PDF, HTML, Microsoft Word XML、DOC、RTF、XLS、PPT、DBF、CSV、TXT 和 LIT。
附加程序
为即时 OCR 附加的 ABBYY Screenshot Reader 实用程序
ABBYY Screenshot Reader 是一个易用的工具,可以让您迅速获取屏幕图像并且允许您从屏幕进行“即时” OCR。它对摘取文本、表格或者浏览器页面图像、flash 介绍, Windows Explorer “文件”菜单或者错误消息来说是很理想的。当您想要从 PDF 或图像文件摘取小的节录或文本中的几个句子时, Screenshot Reader 也是一个理想的“快速 OCR”工具。作为对注册用户的奖励,ABBYY Screenshot Reader 与 ABBYY FineReader 8.0 专业版同时发行。
与Word 协同
您可以从 Microsoft Word 内部启动 ABBYY FineReader,扫描纸质文档并将识别结果置入您正在操作的文档中而不用离开 Word。
当导出文件到 Microsoft Word 2003 时, FineReader 自动地打开原文件的一张嵌入视图,允许您同时编辑和查验您的文档,这就不需要在两种应用程序之间切换。
文本编辑
多分栏所见即所得文本编辑器允许您在编辑期间查看扫描文档的完整版式,因此您可以在导出它之前迅速检查文件。
全文搜索
在 ABBYY FineReader 中创建的任何批处理文件都可以作为一个带有全文搜索功能的小数据库使用。您可以用所有语法形式搜索单词。此功能支持有词典支持的36种语言。
条型码识别
ABBYY FineReader 也支持条型码识别,包括 PDF-417 2D 条码的识别。这对需要处理并索引很大数量的文档为存档的公司来说是很理想的功能。
图像分割工具
图像分割工具允许您分割图像为几个区域并保存各个区域为单独页面。此模式对识别书籍和 PowerPoint 稿件是非常方便的。
易用性
ABBYY FineReader 8.0 有一个新的直观的,友好的用户界面来指引您通过 OCR 过程。 无论您对 OCR 是陌生的还是一个高级用户,使用 FineReader 8.0 工作都是简单和容易的。
支持的部分语言列表:
带有词典支持的语言:
亚美尼亚语(东部,西部,Grabar) 保加利亚语 巴士克语 加泰罗尼亚语克罗地亚语捷克语
荷兰语 (荷兰和比利时) 英语 爱沙尼亚语 芬兰语 法语 希腊语
德语 (新拼法和古拼法) 丹麦语 匈牙利语 意大利语 拉脱维亚语立陶宛语
挪威语 (尼诺斯克语和博克马尔语) 波兰语 罗马尼亚语 俄语 斯洛伐克语 西班牙语
葡萄牙语 (葡萄牙和巴西) 斯洛文尼亚语 瑞典语鞑靼语土耳其语乌克兰语
人工语言:
世界语(Esperanto) 拉丁国际语(Interlingua) 伊多语(Ido) 西方语(Occidental)
格式化语言:
Basic
C/C++
COBOL
Fortran
JAVA
Pascal
简单化学公式(H2O, C2H5OH)
【软件特色】
提升处理效率通过使用全新的黑白模式,当您不需要彩色时,FineReader 11 提供的处理速度提高 30%。此外,该程序有效利用了多核处理器的优势,使转换速度更快。
创建电子书灵活多变
扫描纸质书并将它们转换为 ePub 和 fb2 格式,以便在路途上用您的 iPad、平板电脑或最喜欢的便携设备进行阅读。或者,直接将它们发送至您的 Kindle 帐户。将纸质书或文章转换为相应的电子书格式,以便将它们添加到您的电子图书馆或档案中。
Office支持
FineReader 11 将文档和 PDF 文件的图像直接识别和转换为 OpenOffice Writer 格式
(ODT),准确保留它们的本机布局及格式。您只需点击几次鼠标就可以轻松地将文档添加到您
的 *.odt 档案。
增强用户界面
增强的样式编辑器允许您在一个界面友好的窗口中设置所有样式参数。所有的更改会立即应用于整个文档。
在 FineReader 文档中组织页面,从而获取更佳的布局保留。
当程序启动后,立即启动文档转换,就可以更容易访问所有基本或高级转换任务。
配备有强大的图像编辑工具扩充组的下一代相机 OCR
FineReader 11 提供了一套强大的的新图像编辑工具,包括亮度和对比度滑块以及水平工具,确保您能获得更准确的结果并提高图像参数。
OCR 准确度
由于可更好地检测文档样式、脚注、页眉、页脚和图片标题,最大程度地减少编辑已转换文档所需的时间。
优化PDF 输出
PDF 文件的三个预定义的图像设置根据您的需求提供了优化的结果 – 最好的质量、压缩大小或平衡模式。新识别语言阿拉伯语、越南语和土库曼语(拉丁字母 )。
支持名片输入
使用名片阅读器,快速将纸质名片转换为电子联系人(仅 Corporate Edition 提供此功能)
【软件教程】
Abbyy Finereader V11中文版安装教程从本站下载解压Abbyy Finereader V11软件
这是我下载的,压缩包资源包括这两个文件
点击安装文件“ABBYY_FineReader_11_Chinese”,开始安装;弹出下图对话框,直接点击 "Install"即可。
进入下图,直接按提示安装
选“我接受”那项,进入界面“安装类型和位置”,选择“典型”安装
和自定义安装位置,一般不建议安装到系统盘
下图我用红圈圈的,根据自己需求选择,点击“安装”
开始正式安装,这个过程需要几分钟,请耐心等待,直至安装完成。
制作PDF电子书文档
使用的是这个工具ABBYY FineReader 11
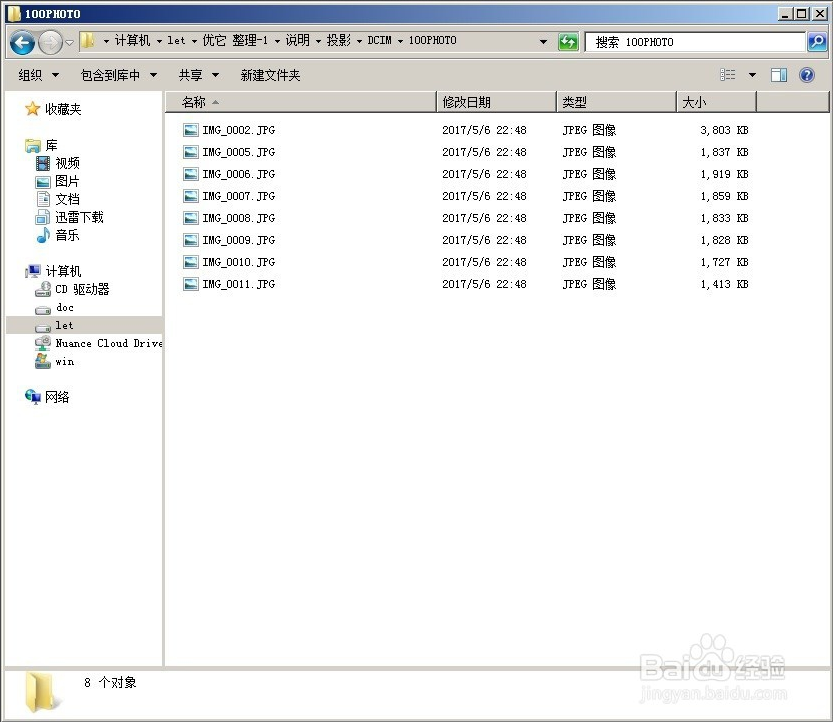
准备的图片格式的文档
准备的PDF格式的文档.
从图示可以看出PDF格式文档比JPG格式略大
打开ABBYY FineReader 11软件,点击左上角文件菜单中“新建文档”选项,可调出“新建任务”面板,我们选择第二项“Adobe PDF”,其中有三个选项“扫描到PDF/A图像”、“文件(PDF/图像)至PDF/A图像”、“照片至PDF/A”,其中我们选择第二项”、“文件(PDF/图像)至PDF/A图像“,这一步骤的目的是把文件或图片转化为PDF电子书格式
选择文件打开后,出现“生成中”、“正在识别该文档”字样,等待进度条走完即可。
处理完成可能出现未识别字符字样,我也不知道怎么处理,好像也没啥影响。
图片文档处理结束出现的是更正分辨率字样,这个我也不清楚是怎么回事儿,但文档确实是处理完也处理好了
然后保存文档即可。我们这样保存:鼠标点击文件菜单下选择“将文档另存为”选项下“PDF/A文档”选项并确定,即可得到需要的PDF文件了。
把PDF转成可编辑文件
首先我们要做的就是打开一个需要转换的PDF文件,然后看一下这个文件里面有几种语言,是不是有表格、图片等
然后运行ABBYY finereader 11,点击欢迎界面“文档语言”下拉选择中的更多语言,弹出“语言编辑器”界面,我们设置好PDF文件中所包含的几种语言。
因为文件文件中有C++语言的内容,而ABBYY finereader 中正好也有C++的选择,那么我们就毫不犹豫的打上勾。设置完毕,点击右下角的“确定”按键。
回到任务界面,我们是想把PDF转成可编辑的word文件,所以我们点击中间的“文件(PDF/图片)到Microsoft Word”一项
弹出文件选择窗口,选择需要转换的PDF文件,注意打开窗口的左下角那几个选项,默认都是打勾的,如果不需要的话可以去掉勾,然后点击“打开”按键。
ABBYY finereader开始加载文件,并且自动OCR识别处理。如果页数比较多的话,可能需要花费一些时间,需要耐心等待一下。
由于自动识别会有一些错误,那么我就可以用手动工具进行修正。我们可以选择不同的工具来修正,比如表格被识别成了普通文字,中间没有线框了,那么我们选择“表格”工具,然后把文件中的表格的区域选出来,然后右键“读取区域”就能够手动识别成表格了。还有如果带有文字的图片被自动识别成了文字了,那么我们可以选择图片工具选出页面中的图片区域,然后在你识别本页面其他部分文字的时候,这个区域就会被识别成图片了。
“编辑图像”按键是用来预处理扫描页图片的,因为扫描页有时候会有倾斜、对比度不好、变形等问题,那么先对图像修正一下可以大幅度提高识别的准确率,调整完以后点击右上角的“退出图像编辑器”按键就可以回到上一界面。
识别完毕以后,选择菜单来的“文件”---“将文档另存为”---“Microsoft Word文档”(如果你需要保存为其他格式你可以自己选择)。
弹出保存对话框,选择保存路径,如果需要保存完就打开文件的话,记得勾选下面的“保存后打开文档”选项,如果电脑配置不高的话不建议勾选此项,因为ABBYY finereader本身比较耗内存,然后再打开word的话电脑可能会比较卡。保存完文件,转换过程就基本结束了。
我们打开保存好的word文件,看看转换的效果怎么样。识别的区域基本上正常,中文英文、图像都可以识别出来,版面略微有些错位,不过还是含有部分错误,我们需要自己修改一下,但是这个已经可以大大降低我们的录入强度了。
【常见问题】
什么是OCR?假设你想要数字化一本杂志的文章或印刷合同。你可能需要花时间重新输入,然后纠正错字。或者,你可以使用扫描仪(或数码相机)和光学字符识别软件只需要花费几分钟转换成数字格式,的所有材料。
泰比(ABBYY) FineReader 11 简体中文版是泰比(ABBYY)专为中国市场设计的本地版本,拥有于全球最通用的泰比(ABBYY)FineReader 11 OCR文字识别软件等同的功能。
轻松一个点击即可生成电子化的文档!
泰比(ABBYY)FineReader提供直观的文件扫描和转换成可编辑、可搜索的电子格式工具。泰比(ABBYY)FineReader可以识别和转换几乎所有打印的文档类型,包括书籍、志上的文章与复杂的布局、表格和电子表格,甚至以准确的精度发传真。
使用ABBYY FineReader 11时我需要扫描仪吗?
不需要扫描仪。无需使用扫描仪来运行该程序,可以使用图像文件,如数码相机拍摄的照片,没有文本层的PDF文件。
什么样的扫描仪与FineReader 11兼容?
ABBYY FineReader 11支持所有TWAIN-和WIA-兼容的扫描仪,多功能周边设备(MFPs)和一体化设备,可以在Avision、Brother(兄弟)、Canon(佳能)、Epson(爱普生)、Fujitsu(富士通)、HP(惠普)、Kodak(柯达)、Lexmark、 Microtek、Mustek、Oki、Panasonic、Plustek、Ricoh、Visioneer、VuPoint、Xerox和其他很多品牌提供的型号中找到这样的扫描仪。
哪种设置是识别目的的最佳扫描设置?
标准文本(字体大小10及更大)300dpi分辨率,小号字体(9号及更小)文本400-600dpi分辨率,灰阶颜色模式。
ABBYY FineReader 11可以捕获手写文本吗?
ABBYY FineReader 11只能捕获打印文本。
软件重新安装之后激活码会发生改变吗?我需要重新购买吗?
软件重新安装之后激活码不变,除非电脑硬件配置发生大的变化—比如,如果电脑硬盘重新格式化了,或者操作系统重新安装或改变,在这种情况下需要再次激活程序,获取新的激活码。
“词典支持”是什么意思?
词典支持允许在单词层面二次分析文本元素,有了词典支持,程序可以确保更加精确的分析和文档识别,简化识别结果的进一步验证,ABBYY FineReader 12提供48种语言的词典支持。